жСШељХиЗ™пЉЪ
http://www.blogjava.net/zhenandaci/archive/2009/02/13/254519.html
дЄКеЫЮиѓіеИ∞еѓєдЇОжЦЗжЬђеИЖз±їињЩж†ЈзЪДдЄНйАВеЃЪйЧЃйҐШпЉИжЬЙдЄАдЄ™дї•дЄКиІ£зЪДйЧЃйҐШзІ∞дЄЇдЄНйАВеЃЪйЧЃйҐШпЉЙпЉМйЬАи¶БжЬЙдЄАдЄ™жМЗж†ЗжЭ•и°°йЗПиІ£еЖ≥жЦєж°ИпЉИеН≥жИСдїђйАЪињЗиЃ≠зїГеїЇзЂЛзЪДеИЖз±їж®°еЮЛпЉЙзЪДе•љеЭПпЉМиАМеИЖз±їйЧійЪФжШѓдЄАдЄ™жѓФиЊГе•љзЪДжМЗж†ЗгАВ
еЬ®ињЫи°МжЦЗжЬђеИЖз±їзЪДжЧґеАЩпЉМжИСдїђеПѓдї•иЃ©иЃ°зЃЧжЬЇињЩж†ЈжЭ•зЬЛеЊЕжИСдїђжПРдЊЫзїЩеЃГзЪДиЃ≠зїГж†ЈжЬђпЉМжѓПдЄАдЄ™ж†ЈжЬђзФ±дЄАдЄ™еРСйЗПпЉИе∞±жШѓйВ£дЇЫжЦЗжЬђзЙєеЊБжЙАзїДжИРзЪДеРСйЗПпЉЙеТМдЄАдЄ™ж†ЗиЃ∞пЉИж†Зз§ЇеЗЇињЩдЄ™ж†ЈжЬђе±ЮдЇОеУ™дЄ™з±їеИЂпЉЙзїДжИРгАВе¶ВдЄЛпЉЪ
Di=(xi,yi)
xiе∞±жШѓжЦЗжЬђеРСйЗПпЉИзїіжХ∞еЊИйЂШпЉЙпЉМyiе∞±жШѓеИЖз±їж†ЗиЃ∞гАВ
еЬ®дЇМеЕГзЪДзЇњжАІеИЖз±їдЄ≠пЉМињЩдЄ™и°®з§ЇеИЖз±їзЪДж†ЗиЃ∞еП™жЬЙдЄ§дЄ™еАЉпЉМ1еТМ-1пЉИзФ®жЭ•и°®з§Їе±ЮдЇОињШжШѓдЄНе±ЮдЇОињЩдЄ™з±їпЉЙгАВжЬЙдЇЖињЩзІНи°®з§Їж≥ХпЉМжИСдїђе∞±еПѓдї•еЃЪдєЙдЄАдЄ™ж†ЈжЬђзВєеИ∞жЯРдЄ™иґЕеє≥йЭҐзЪДйЧійЪФпЉЪ
ќіi=yi(wxi+b)
ињЩдЄ™еЕђеЉПдєНдЄАзЬЛж≤°дїАдєИз•ЮзІШзЪДпЉМдєЯиѓідЄНеЗЇдїАдєИйБУзРЖпЉМеП™жШѓдЄ™еЃЪдєЙиАМеЈ≤пЉМдљЖжИСдїђеБЪеБЪеПШжНҐпЉМе∞±иГљзЬЛеЗЇдЄАдЇЫжЬЙжДПжАЭзЪДдЄЬи•њгАВ
й¶ЦеЕИж≥®жДПеИ∞е¶ВжЮЬжЯРдЄ™ж†ЈжЬђе±ЮдЇОиѓ•з±їеИЂзЪДиѓЭпЉМйВ£дєИwxi+b>0пЉИиЃ∞еЊЧдєИпЉЯињЩжШѓеЫ†дЄЇжИСдїђжЙАйАЙзЪДg(x)=wx+bе∞±йАЪињЗе§ІдЇО0ињШжШѓе∞ПдЇО0жЭ•еИ§жЦ≠еИЖз±їпЉЙпЉМиАМyiдєЯе§ІдЇО0пЉЫиЛ•дЄНе±ЮдЇОиѓ•з±їеИЂзЪДиѓЭпЉМйВ£дєИwxi+b<0пЉМиАМyiдєЯе∞ПдЇО0пЉМињЩжДПеС≥зЭАyi(wxi+b)жАїжШѓе§ІдЇО0зЪДпЉМиАМдЄФеЃГзЪДеАЉе∞±з≠ЙдЇО|wxi+b|пЉБпЉИдєЯе∞±жШѓ|g(xi)|пЉЙ
зО∞еЬ®жККwеТМbињЫи°МдЄАдЄЛељТдЄАеМЦпЉМеН≥зФ®w/||w||еТМb/||w||еИЖеИЂдї£жЫњеОЯжЭ•зЪДwеТМbпЉМйВ£дєИйЧійЪФе∞±еПѓдї•еЖЩжИР
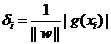
ињЩдЄ™еЕђеЉПжШѓдЄНжШѓзЬЛдЄКеОїжЬЙзВєзЬЉзЖЯпЉЯж≤°йФЩпЉМињЩдЄНе∞±жШѓиІ£жЮРеЗ†дљХдЄ≠зВєxiеИ∞зЫізЇњg(x)=0зЪДиЈЭз¶їеЕђеЉПеШЫпЉБпЉИжО®еєњдЄАдЄЛпЉМжШѓеИ∞иґЕеє≥йЭҐg(x)=0зЪДиЈЭз¶їпЉМ g(x)=0е∞±жШѓдЄКиКВдЄ≠жПРеИ∞зЪДеИЖз±їиґЕеє≥йЭҐпЉЙ
е∞ПTipsпЉЪ||w||жШѓдїАдєИзђ¶еПЈпЉЯ||w||еПЂеБЪеРСйЗПwзЪДиМГжХ∞пЉМиМГжХ∞жШѓеѓєеРСйЗПйХњеЇ¶зЪДдЄАзІНеЇ¶йЗПгАВжИСдїђеЄЄиѓізЪДеРСйЗПйХњеЇ¶еЕґеЃЮжМЗзЪДжШѓеЃГзЪД2-иМГжХ∞пЉМиМГжХ∞жЬАдЄАиИђзЪД谮积嚥еЉПдЄЇp-иМГжХ∞пЉМеПѓдї•еЖЩжИРе¶ВдЄЛи°®иЊЊеЉП
еРСйЗПw=(w1, w2, w3,вА¶вА¶ wn)
еЃГзЪДp-иМГжХ∞дЄЇ
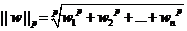
зЬЛзЬЛжККpжНҐжИР2зЪДжЧґеАЩпЉМдЄНе∞±жШѓдЉ†зїЯзЪДеРСйЗПйХњеЇ¶дєИпЉЯељУжИСдїђдЄНжМЗжШОpзЪДжЧґеАЩпЉМе∞±еГП||w||ињЩж†ЈдљњзФ®жЧґпЉМе∞±жДПеС≥зЭАжИСдїђдЄНеЕ≥ењГpзЪДеАЉпЉМзФ®еЗ†иМГжХ∞йГљеПѓдї•пЉЫжИЦиАЕдЄКжЦЗеЈ≤зїПжПРеИ∞дЇЖpзЪДеАЉпЉМдЄЇдЇЖеПЩињ∞жЦєдЊњдЄНеЖНйЗНе§НжМЗжШОгАВ
ељУзФ®ељТдЄАеМЦзЪДwеТМbдї£жЫњеОЯеАЉдєЛеРОзЪДйЧійЪФжЬЙдЄАдЄ™дЄУйЧ®зЪДеРНзІ∞пЉМеПЂеБЪеЗ†дљХйЧійЪФпЉМеЗ†дљХйЧійЪФжЙАи°®з§ЇзЪДж≠£жШѓзВєеИ∞иґЕеє≥йЭҐзЪДжђІж∞ПиЈЭз¶їпЉМжИСдїђдЄЛйЭҐе∞±зЃАзІ∞еЗ†дљХйЧійЪФдЄЇвАЬиЈЭз¶ївАЭгАВдї•дЄКжШѓеНХдЄ™зВєеИ∞жЯРдЄ™иґЕеє≥йЭҐзЪДиЈЭз¶їпЉИе∞±жШѓйЧійЪФпЉМеРОйЭҐдЄНеЖНеМЇеИЂињЩдЄ§дЄ™иѓНпЉЙеЃЪдєЙпЉМеРМж†ЈеПѓдї•еЃЪдєЙдЄАдЄ™зВєзЪДйЫЖеРИпЉИе∞±жШѓдЄАзїДж†ЈжЬђпЉЙеИ∞жЯРдЄ™иґЕеє≥йЭҐзЪДиЈЭз¶їдЄЇж≠§йЫЖеРИдЄ≠з¶їиґЕеє≥йЭҐжЬАињСзЪДзВєзЪДиЈЭз¶їгАВдЄЛйЭҐињЩеЉ†еЫЊжЫіеК†зЫіиІВзЪДе±Хз§ЇеЗЇдЇЖеЗ†дљХйЧійЪФзЪДзО∞еЃЮеРЂдєЙпЉЪ

HжШѓеИЖз±їйЭҐпЉМиАМH1еТМH2жШѓеє≥и°МдЇОHпЉМдЄФињЗз¶їHжЬАињСзЪДдЄ§з±їж†ЈжЬђзЪДзЫізЇњпЉМH1дЄОHпЉМH2дЄОHдєЛйЧізЪДиЈЭз¶їе∞±жШѓеЗ†дљХйЧійЪФгАВ
дєЛжЙАдї•е¶Вж≠§еЕ≥ењГеЗ†дљХйЧійЪФињЩдЄ™дЄЬи•њпЉМжШѓеЫ†дЄЇеЗ†дљХйЧійЪФдЄОж†ЈжЬђзЪДиѓѓеИЖжђ°жХ∞йЧіе≠ШеЬ®еЕ≥з≥їпЉЪ

еЕґдЄ≠зЪДќіжШѓж†ЈжЬђйЫЖеРИеИ∞еИЖз±їйЭҐзЪДйЧійЪФпЉМR=max ||xi|| i=1,...,nпЉМеН≥RжШѓжЙАжЬЙж†ЈжЬђдЄ≠пЉИxiжШѓдї•еРСйЗПи°®з§ЇзЪДзђђiдЄ™ж†ЈжЬђпЉЙеРСйЗПйХњеЇ¶жЬАйХњзЪДеАЉпЉИдєЯе∞±жШѓиѓідї£и°®ж†ЈжЬђзЪДеИЖеЄГжЬЙе§ЪдєИеєњпЉЙгАВеЕИдЄНењЕињљз©ґиѓѓеИЖжђ°жХ∞зЪДеЕЈдљУеЃЪдєЙеТМжО®еѓЉињЗз®ЛпЉМеП™и¶БиЃ∞еЊЧињЩдЄ™иѓѓеИЖжђ°жХ∞дЄАеЃЪз®ЛеЇ¶дЄКдї£и°®еИЖз±їеЩ®зЪДиѓѓеЈЃгАВиАМдїОдЄКеЉПеПѓдї•зЬЛеЗЇпЉМиѓѓеИЖжђ°жХ∞зЪДдЄКзХМзФ±еЗ†дљХйЧійЪФеЖ≥еЃЪпЉБпЉИељУзДґпЉМжШѓж†ЈжЬђеЈ≤зЯ•зЪДжЧґеАЩпЉЙ
иЗ≥ж≠§жИСдїђе∞±жШОзЩљдЄЇдљХи¶БйАЙжЛ©еЗ†дљХйЧійЪФжЭ•дљЬдЄЇиѓДдїЈдЄАдЄ™иІ£дЉШеК£зЪДжМЗж†ЗдЇЖпЉМеОЯжЭ•еЗ†дљХйЧійЪФиґКе§ІзЪДиІ£пЉМеЃГзЪДиѓѓеЈЃдЄКзХМиґКе∞ПгАВеЫ†ж≠§жЬАе§ІеМЦеЗ†дљХйЧійЪФжИРдЇЖжИСдїђиЃ≠зїГйШґжЃµзЪДзЫЃж†ЗпЉМиАМдЄФпЉМдЄОдЇМжККеИАдљЬиАЕжЙАеЖЩзЪДдЄНеРМпЉМжЬАе§ІеМЦеИЖз±їйЧійЪФеєґдЄНжШѓSVMзЪДдЄУеИ©пЉМиАМжШѓжЧ©еЬ®зЇњжАІеИЖз±їжЧґжЬЯе∞±еЈ≤жЬЙзЪДжАЭжГ≥гАВ
еИЖдЇЂеИ∞пЉЪ





зЫЄеЕ≥жО®иНР
SVMеЕ•йЧ®пЉИдЄЙпЉЙзЇњжАІеИЖз±їеЩ®Part 2 SVMеЕ•йЧ®пЉИеЫЫпЉЙзЇњжАІеИЖз±їеЩ®зЪДж±ВиІ£вАФвАФйЧЃйҐШзЪДжППињ∞Part1 SVMеЕ•йЧ®пЉИдЇФпЉЙзЇњжАІеИЖз±їеЩ®зЪДж±ВиІ£вАФвАФйЧЃйҐШзЪДжППињ∞Part2 SVMеЕ•йЧ®пЉИеЕ≠пЉЙзЇњжАІеИЖз±їеЩ®зЪДж±ВиІ£вАФвАФйЧЃйҐШзЪДиљђеМЦпЉМзЫіиІВиІТеЇ¶ SVMеЕ•йЧ®пЉИдЄГпЉЙдЄЇдљХ...
зЃАеНХзЪДSVMзЇњжАІеИЖз±їзЪДдїњзЬЯеЃЮй™МпЉМеМЕжЛђжµЛиѓХжХ∞жНЃиЈЯжЇРз†БпЉМжШУе≠¶
дљњзФ®SVMеѓєжХ∞жНЃињЫи°МеИЖз±їпЉМдЄФињЫи°МзїУжЮЬжШЊз§ЇпЉМеПѓжЯ•йШЕSVMзЫЄеЕ≥иµДжЦЩпЉМеѓєиѓ•дї£з†БеПКеЕґзЃЧж≥ХињЫи°МињЫдЄАж≠•дЇЖиІ£гАВ
йЗЗзФ®matlabињЫи°МжФѓжМБеРСйЗПжЬЇsvmзЪДзЇњжАІеИЖз±їпЉМжѓПдЄАеП•йГљжЬЙиѓ¶е∞љзЪДиІ£йЗКпЉМжЦєдЊње§ІеЃґе≠¶дє†дЇ§жµБ
еИ©зФ®жФѓжМБеРСйЗПжЬЇ(SVM)ж±ВиІ£еИЖз±їйЧЃйҐШпЉМеМЕеРЂзЇњжАІеИЖз±їжЦєж≥ХпЉМйЭЮзЇњжАІеИЖз±їжЦєж≥ХпЉМйЂШжЦѓж†ЄеИЖз±їжЦєж≥Хз≠Йе∞ПеЃЮдЊЛ
SVM-йЭЮзЇњжАІеИЖз±їжХ∞жНЃйЫЖ
еИЖз±їеЩ®иЃЊиЃ°дєЛзЇњжАІеИЖз±їеЩ®еТМзЇњжАІSVM(Matlabдї£з†Б еЕЈдЉСиѓЈеПВиАГжЬђдЇЇеНЪеЃҐпЉЪ http://blog.csdn.net/ranchlai/article/details/10303031
зЇњжАІжФѓжМБеРСйЗПжЬЇиЃ≠зїГжЦЗдїґ MATLABдї£з†Б еПѓињРи°М
зЇњжАІSVMеИЖз±їеЩ®
ж®°еЉПиѓЖеИЂ еМЧдЇђе§Іе≠¶ жЬђзІСзФЯиѓЊз®Л иѓЊдїґ пЉИеМЕжЛђиіЭеПґжЦѓж®°еЮЛгАБжЬАињСйВїгАБSVMгАБзЇњжАІдЄОйЭЮзЇњжАІеИЖз±їеЩ®гАБboostingгАБзїЯиЃ°е≠¶дє†гАБйЭЮзЫСзЭ£е≠¶дє†з≠ЙпЉЙ
SVMеЕ•йЧ®йЬАи¶БзЪД搥ињОдЄЛиљљ
еЫЫзІНжµБи°МзЪДSVMеИЖз±їеЩ®еЈ•еЕЈзЃ±пЉМеЊИеЕ®гАВrar
еЯЇдЇОSVMеЃЮзО∞дЇЖеѓєдЇОжХ∞жНЃзЪДзЇњжАІеИЖз±їпЉМеєґдЄФйЩДеЄ¶дЇЖдљњзФ®зЪДжХ∞жНЃ
ж®°еЉПиѓЖеИЂзЇњжАІSVMеИЖз±їеЩ®liblinear-1.5ж®°еЉПиѓЖеИЂзЇњжАІSVMеИЖз±їеЩ®liblinear-1.5ж®°еЉПиѓЖеИЂзЇњжАІSVMеИЖз±їеЩ®liblinear-1.5ж®°еЉПиѓЖеИЂзЇњжАІSVMеИЖз±їеЩ®liblinear-1.5ж®°еЉПиѓЖеИЂзЇњжАІSVMеИЖз±їеЩ®liblinear-1.5
SVMжШѓдЄАдЄ™зЇњжАІеИЖз±їеЩ®пЉМдљЖжШѓжѓФиµЈдЄАиИђзЪДзЇњжАІеИЖз±їеЩ®пЉМSVMйАЙжЛ©зЪДжШѓй≤Бж£ТжАІжЬАе•љгАБж≥ЫеМЦиГљеКЫжЬАеЉЇзЪДеИЖзХМиґЕеє≥йЭҐпЉМе∞ЖжХ∞жНЃеИЖдЄЇдЄ§дЄ™йГ®еИЖгАВиАМйАЙжЛ©жЬАе•љзЪДеЖ≥з≠ЦиЊєзХМжШѓж†єжНЃжФѓжМБеРСйЗПжЙАеЖ≥еЃЪзЪДпЉМдєЯе∞±жШѓиѓіеѓєдЇОжХідЄ™жХ∞жНЃйЫЖпЉМжИСеП™йЬАи¶БжФѓжМБеРСйЗП...
SVMйЭЮзЇњжАІж†ЄеЗљжХ∞з®ЛеЇП
иѓ•жЦєж≥ХеЯЇдЇОдЄЇиЃ≠зїГйЫЖдЄ≠зЪДжѓПдЄ™з§ЇдЊЛиЃ≠зїГеНХзЛђзЪДзЇњжАІSVMеИЖз±їеЩ®гАВеЫ†ж≠§пЉМињЩдЇЫз§ЇдЊЛSVMдЄ≠зЪДжѓПдЄАдЄ™йГљзФ±дЄАдЄ™ж≠£еЃЮдЊЛеТМжХ∞зЩЊдЄЗдЄ™иіЯеЃЪдєЙгАВе∞љзЃ°жѓПдЄ™ж£АжµЛеЩ®еѓєеЕґз§ЇдЊЛйГљйЭЮеЄЄзЙєеЃЪпЉМдљЖжИСдїђдїОзїПй™МдЄКиІВеѓЯеИ∞пЉМињЩж†ЈзЪДз§ЇдЊЛ-SVMзЪДйЫЖжИРжПРдЊЫдЇЖдї§дЇЇ...
зФ®SVMжЦєж≥ХеИґдљЬзЪДеИЖз±їеЩ®1 Training Click вАЬLearning вАЬ from Toolbar or Menu, a dialog will appears like following : You can browse and choose the training sample data file(*.trn), or write the data ...
зФ®зЇњжАІSVMиІ£еЖ≥йЭЮзЇњжАІйЧЃйҐШпЉМеЯЇдЇОMATLABеє≥еП∞зЪДжХ∞жНЃеИЖз±їдї£з†Б
MatlabзЪДSVMеЕ•йЧ®жХізРЖжЦЗж°£-SVMеЕ•йЧ®.rar й¶ЦеЕИйЭЮеЄЄжДЯи∞ҐmatlabдЄ≠жЦЗиЃЇеЭЫзЪДдЇЇеЈ•жЩЇиГљзЙИдЄїеЬ®SVMзЯ•иѓЖжЦєйЭҐеБЪзЪДиі°зМЃпЉМгАКSVMеЕ•йЧ®гАЛжЦЗж°£е∞±жШѓеЬ®иЃЇеЭЫдЄКдЄЛзЪДпЉМдљЖжШѓжЬЙдЄАзЉЇзВєе∞±жШѓжЭњдє¶дЄН姙啚зЬЛпЉМеЫ†ж≠§жИСе∞Жиѓ•жЦЗж°£и∞ГжХідЇЖдЄАдЄЛпЉМзЬЛдЄКеОїиИТжЬН...